
Temporal Localization
Identify which connection happened first, last, next, or most recently relative to an assembly state.
Furniture assembly as a spatio-temporal stress test
Evaluating Spatio-Temporal Understanding in Large Vision-Language Models through Furniture Assembly
Venue

Challenge!
Make your pick, reveal the models' answers, and see if your reasoning wins!
Overview
Many applications, such as furniture assembly and cooking, require step-by-step fine-grained spatio-temporal understanding of videos, which is not sufficiently evaluated in current video understanding benchmarks for Large Vision-Language Models (LVLMs). To fill this gap, we propose a novel multimodal question-answering benchmark, FLAT-PACKBENCH, based on furniture assembly videos. We frame fine-grained questions for nuanced tasks, including temporal ordering of assembly actions, temporal localization of assembly states, understanding part mating, and tracking, as multiple-choice questions paired with visual prompts highlighting relevant parts as references for the questions.
Our experiments show that even state-of-the-art LVLMs struggle: OpenAI's latest GPT-5 model achieves about 38% accuracy, trailing far behind human performance of about 94%. We look deeper into model performance and show how models struggle with spatio-temporal reasoning tasks, such as tracking and contact detection, required for the tasks in our benchmark. Our benchmark suggests that, despite rapid progress, current LVLMs (and computer vision systems in general) have limited capability to understand the temporal evolution of complex scenes.
Benchmark
Identify which connection happened first, last, next, or most recently relative to an assembly state.
Recover the exact order in which parts or part-pairs become physically connected.
Determine whether two labeled parts are connected in the fully assembled furniture.
Match labeled parts across two states, requiring object identity through occlusion and motion.
FLAT-PACKBENCH starts from IKEA-Manuals-At-Work (IMaW) [Liu et al., NeurIPS D&B 2024], an in-the-wild collection of IKEA furniture assembly videos with 3D part models, key frames, segmentation masks, poses, and sub-assembly annotations. Because IMaW segmentations cover only parts being connected in selected key frames and are often provided at sub-assembly rather than individual-part granularity, we extend the annotations with fine-grained part segmentations on 343 frames across 50 videos and add part-level connection events specifying which parts connect, when, and to what.
The benchmark evaluates both trimmed videos, where text-only instruction-card segments are removed from raw videos, and keyframe videos, which retain only salient assembly states. Visual prompts refer unambiguously to furniture parts: text descriptions can be ambiguous in symmetric assemblies and can encourage models to rely on common-sense furniture priors rather than the provided visual input. The resulting questions span mating, tracking, temporal ordering, and temporal localization. Although annotations and templates allow automatic generation, final questions are manually curated to avoid shortcuts from static prompt cues, already-connected parts, or weak distractors.
Dataset Viewer
Evaluation
Prompt construction. Each evaluation prompt consists of an assembly video, one or two visual prompts, the multiple-choice question, and fixed task instructions describing the input format. We evaluate both keyframe videos, which show salient assembly states, and trimmed videos, which remove text-only instruction-card segments from the raw videos. Visual prompts are supplied in three settings: Mixed-Media, where prompt images are provided separately from the video; Collage, where prompt images are fixed alongside every video frame; and Concat, where prompt images are prepended as the first one or two video frames. The expandable viewer below shows examples of these prompt types from the supplementary material.
Metric. Models answer with an option label, and performance is measured using exact-match multiple-choice accuracy. Results are reported as micro-average accuracy across the benchmark and as per-category accuracy for temporal ordering, temporal localization, tracking, and mating.
Key Results
micro-average accuracy
InternVL3-78B in the paper's main benchmark setting
OpenAI GPT-5 in the paper's main benchmark setting
| Model | Prompt | Video | Micro | 95% CI | TORD | TLOC | TRACK | MATE |
|---|
Current LVLMs remain far behind humans on FLAT-PACKBENCH: human evaluators reach 94.18% micro-average accuracy, while all model families stay below 42%.
Proprietary models. GPT-5 is the strongest proprietary model at 37.71% micro-average accuracy, followed by Gemini 2.5 Pro at 33.72% and Gemini 3.1 Pro at 32.89%. These scores are only modestly above the frequency-chance baseline of 26.74%, showing that even leading closed models struggle with the benchmark's fine-grained spatio-temporal reasoning.
Open models. The strongest overall result comes from InternVL3-78B, which reaches 41.03% micro-average accuracy, with Qwen2.5-VL-72B close behind at 40.37%. Open models are competitive with proprietary systems, but performance varies widely across model families and sizes, with several models only slightly above chance.
Specialized models. Despite being trained specifically for fine-grained region-specific questions, PerceptionLM and VideoRefer perform poorly, likely due to a mismatch between their training data, which feature relatively simple videos with few fine-grained interactions, and the complex, multi-part interactions in FLAT-PACKBENCH. Still, PerceptionLM-8B is competitive with much larger models (e.g., Qwen2.5-VL-32B), suggesting value in training on data rich in fine-grained interactions. Temporal sensitivity also helps ArrowRL beat its base checkpoint (Qwen2.5-VL-7B), especially on temporal ordering (TORD).
Taken together, these results indicate that current LVLMs - proprietary, open, and specialized - remain far from achieving the strong, reliable spatio-temporal understanding skills that humans demonstrate on FLAT-PACKBENCH.
Tracking is a major failure mode in the results above. This is especially important because tracking requires temporal understanding: a model has to preserve object identity across occlusions, camera motion, repeated part shapes, and changing viewpoints. The video is the only input that shows how a labeled part in Image A becomes a labeled part in Image B, so poor tracking raises a direct question: are LVLMs actually using the temporal information in the video?
To test this, we evaluate an image-only version of the benchmark. The assembly video is removed, and humans and models answer using only the visual prompts, together with the multiple-choice question. If the tasks truly require temporal information, human performance should drop sharply. If LVLMs are using the video effectively, their performance should also degrade substantially when video is removed.
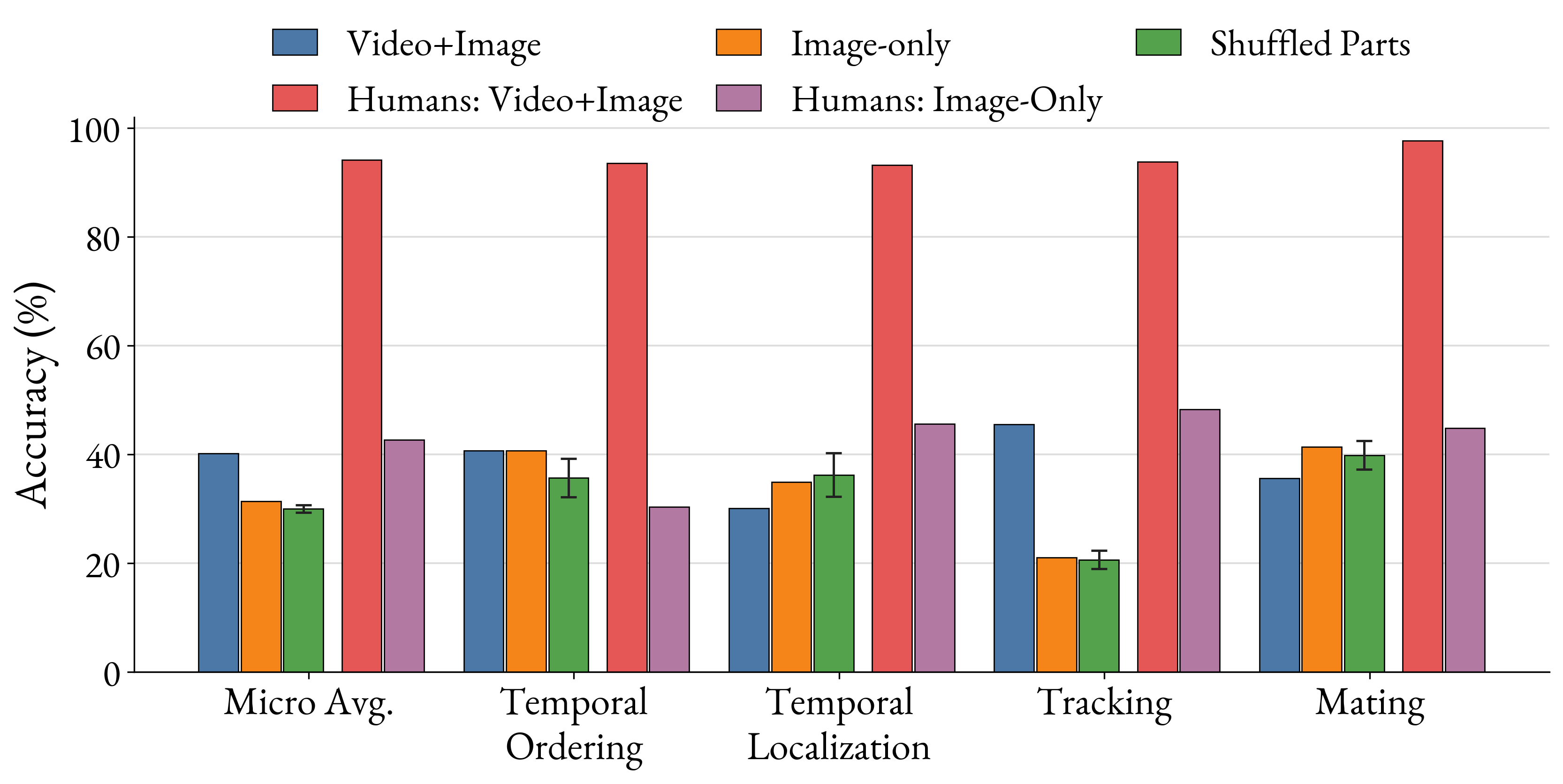
Our results show that human performance drops sharply in the image-only setting, confirming that the questions require video to answer reliably. Qwen2.5-VL-72B also drops overall, but the drop is concentrated in tracking. Temporal Localization and Mating stay stable or improve, suggesting that the model can often rely on static visual cues, part appearance, part position, and commonsense assembly priors rather than using temporal evidence in the video.
The Shuffled Parts condition checks for a part ID bias. In some Temporal Ordering questions, the numeric part IDs can correlate with the connection order, giving the model a shortcut that does not require temporal reasoning. The drop in Temporal Ordering after shuffling shows that part-number ordering was one shortcut the LVLM could exploit.
Overall, these results suggest that LVLMs are not using the videos effectively.
We looked at self-explanations to understand why LVLMs were failing on fine-grained spatio-temporal questions. In preliminary experiments, the rationales generated by Qwen2.5-VL-72B mostly paraphrased its selected option, which made them less useful for diagnosing the underlying failure mode.
Gemini 2.5 Pro's thought summaries were substantially richer: they often included timestamps, explicit connection events, and intermediate tracking decisions. We therefore used these summaries to pinpoint where the model's reasoning diverged from the visual evidence.
For the quantitative error analysis, we sampled 200 questions that Gemini 2.5 Pro answered incorrectly, balanced across the four task categories. Human annotators wrote short diagnoses from the thought summaries; we then collated the question text, model thoughts, and annotations, asked Gemini 2.5 Pro to identify five broad error categories, and assigned each example to one or more categories.
Percentages show each category's share among the sampled incorrect questions used for rationale analysis.
Failure to correctly identify an object across the image and video.
Error tracking an object's identity through camera motion, object rotation, or scene cuts.
The chronological sequence of object interactions is wrong.
The model misjudges contact, support, or other physical interactions between parts.
Instruction misinterpretation or faulty conclusions from correct observations.
We show the thought summaries and CoT explanations generated by Gemini 2.5 Pro and Qwen2.5-VL-72B respectively. We conducted this experiment on the Mixed-Media visual prompts using key-frame videos. Pick a question ID from the examples below to view the question; scroll below to select the model, and look at their respective answers and explanations.
For Gemini 2.5 Pro, in addition to the thought summaries, we also show manually-annotated Performance Indicators (red for errors, green for accurate statements) based on the error categories for rationales discussed earlier. Green means that the model's rationale displayed correct understanding in that aspect, while red indicates poor reasoning skills in that category.
We also provide a manually annotated Diagnostic Analysis for each explanation, highlighting what the explanation got right or wrong and what that suggests about the LVLMs spatio-temporal reasoning abilties.
Object grounding and spatio-temporal reasoning are the major error sources, suggesting that the model struggles to understand the fine-grained regional references from the visual prompt and tracking the references through the video.
Many questions in FLAT-PACKBENCH can be decomposed into two lower-level skills: tracking parts through the assembly video and reasoning about when those parts make contact. We therefore evaluated whether a tool-using decomposition could solve the benchmark by isolating those subproblems.
We call the visual programming agent, Temporal Video Agent or TVAnot to be confused with this TVA 😄 for short. TVA uses specialized tools for each stage, including a SAM 2-based tracker for object propagation and a VLM-query function for contact reasoning. The agent writes and executes code that calls these tools, then attempts to map the tool outputs back to the multiple-choice options.
Overall, TVA performs poorly, reaching only 11.79% accuracy, and mostly abstains with a 62.29% abstention rate because it cannot find an answer within the provided option set. Further analysis shows that the issue is not just final answer selection: the tools themselves are often inaccurate on furniture assembly videos. The qualitative examples below show how those tracking and contact-reasoning failures appear during execution.
We show some qualitative examples of TVA in action. Each example includes the benchmark question, the corresponding visual prompt, and a walkthrough video showing the generated tool-execution trace used by the agent.
Beyond the benchmark questions, even simpler tasks (like tracking and contact-reasoning) on the furniture assembly domain are a challenge for the current state-of-the-art.
Conclusion
Our analysis reveals key bottlenecks of LVLMs in finegrained video understanding particularly spatio-temporal reasoning (e.g. keeping track of parts through occlusions, scene cuts, etc.) and region-specific grounding. We also study whether an agentic decomposition of the task can help, but find that current vision tools share similar limitations: even specialized tracking models struggle, and LVLMs fail on simpler subproblems such as contact reasoning.